Monday, April 13th, 2009 11:00 pm
amazon and codefixes - oh, this is something i might know something about!
This is partially to test crossposting.
A possible explanation, gakked from trobadora:
AmazonFail: An Inside Look at What Happened
Note: If they are telling the truth about what happened, this applies. And actually, it would apply if they lied, but worse. One error is one thing, but if this was a deliberate system-wide build that made the change, pretty much the same thing applies, but with less sympathy.
My expertise is not expertise, it is anecdata, but it's also ten builds and fifty emergency releases of professional anecdata, so take that as you will.
I am a professional tester because at some point, it occurred to people that things worked better when there was a level of testing that was specifically designed to mimic the experiences of the average user with a change to a program. Of course, they didn't use average users, they used former caseworkers and programmers, but the point stands.
( a longwinded way of saying, if this isn't a complete and utter lie, it does make sense )
Short version: this matches my testing experience and also tells you more than you ever wanted to know about my daily life and times. YMMV for those who have a different model for code releases and updates.
And to add, again, if this is true, I am seriously feeling for the tech dept right now. Having to do unplanned system-wide fixes sucks. Someone is leaving really unkind post-it notes for the French coder. Not that I ever considered doing that or anything.
ETA: For us, there are two types of builds and fixes: mod (modification) and main (maintenance). The former is actual new things added to the code, like, I don't know, adding an interface or new policy or changing the color scheme. Maintenance is stuff that is already there that broke and needs to be fixed, like suddenly you can't make a page work. Emergency fixes in general are maintenance, something broken that needs fixing, with occasional mods, the legislature did something dramatic.
None of this means they aren't lying and it wasn't deliberate. My department failed an entire build once due to the errors in it.
Actually, the easiest way to find out if it was deliberate is to hunt down whoever did their testing and check the scripts they wrote, or conversely, if amazon does it all automated, the automated testing scripts will also tell you exactly what was being tested. If it was deliberate, there were several scripts specifically created to test this change.
Example:
If I wrote the user script and was running it in a near-field environment.
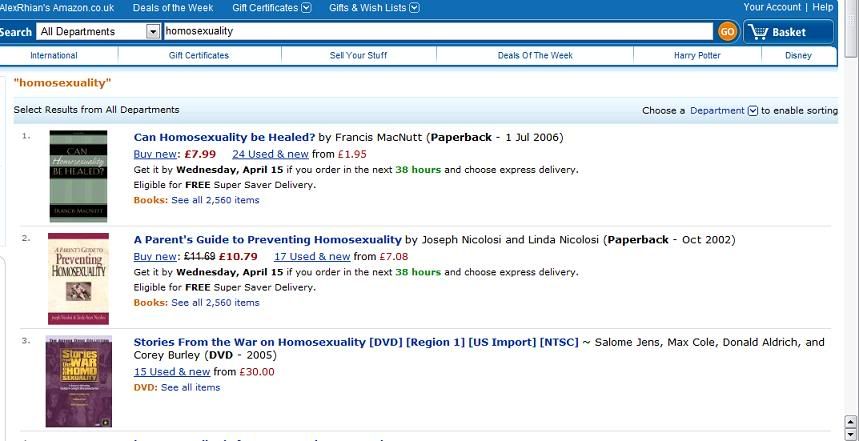
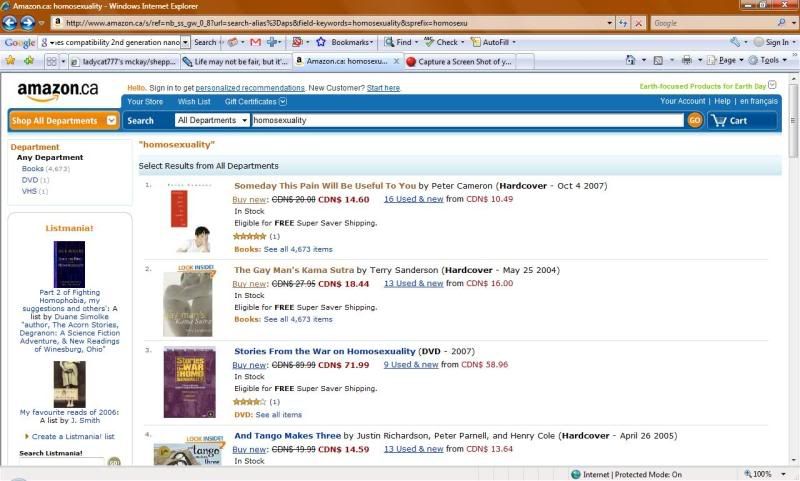
Step Four: Query for Beauty's Punishment from main page.
Expected Result: Does not display.
Actual Result: Does not display.
(add screenshot here)
Step Five: Query for Beauty's Punishment from Books.
Expected Result: Displays.
Actual Result: Displays.
(add screenshot here)
We're like the evidence trail. Generally, a tester has to know what they are supposed to be testing to test it. If this was live beta'ed earlier this year with just a few authors, it still had to, at some point, go through some kind of formal testing procedure and record the results. And there would be a test written specifically to see if X Story Marked Adult would appear if searched from the main page, and one specifically written to check that X Story Marked Adult was showing sales figures, either human-run or automated.
(Crossposted to Livejournal)
A possible explanation, gakked from trobadora:
AmazonFail: An Inside Look at What Happened
Amazon managers found that an employee who happened to work in France had filled out a field incorrectly and more than 50,000 items got flipped over to be flagged as "adult," the source said. (Technically, the flag for adult content was flipped from 'false' to 'true.')
Note: If they are telling the truth about what happened, this applies. And actually, it would apply if they lied, but worse. One error is one thing, but if this was a deliberate system-wide build that made the change, pretty much the same thing applies, but with less sympathy.
My expertise is not expertise, it is anecdata, but it's also ten builds and fifty emergency releases of professional anecdata, so take that as you will.
I am a professional tester because at some point, it occurred to people that things worked better when there was a level of testing that was specifically designed to mimic the experiences of the average user with a change to a program. Of course, they didn't use average users, they used former caseworkers and programmers, but the point stands.
( a longwinded way of saying, if this isn't a complete and utter lie, it does make sense )
Short version: this matches my testing experience and also tells you more than you ever wanted to know about my daily life and times. YMMV for those who have a different model for code releases and updates.
And to add, again, if this is true, I am seriously feeling for the tech dept right now. Having to do unplanned system-wide fixes sucks. Someone is leaving really unkind post-it notes for the French coder. Not that I ever considered doing that or anything.
ETA: For us, there are two types of builds and fixes: mod (modification) and main (maintenance). The former is actual new things added to the code, like, I don't know, adding an interface or new policy or changing the color scheme. Maintenance is stuff that is already there that broke and needs to be fixed, like suddenly you can't make a page work. Emergency fixes in general are maintenance, something broken that needs fixing, with occasional mods, the legislature did something dramatic.
None of this means they aren't lying and it wasn't deliberate. My department failed an entire build once due to the errors in it.
Actually, the easiest way to find out if it was deliberate is to hunt down whoever did their testing and check the scripts they wrote, or conversely, if amazon does it all automated, the automated testing scripts will also tell you exactly what was being tested. If it was deliberate, there were several scripts specifically created to test this change.
Example:
If I wrote the user script and was running it in a near-field environment.
Step Four: Query for Beauty's Punishment from main page.
Expected Result: Does not display.
Actual Result: Does not display.
(add screenshot here)
Step Five: Query for Beauty's Punishment from Books.
Expected Result: Displays.
Actual Result: Displays.
(add screenshot here)
We're like the evidence trail. Generally, a tester has to know what they are supposed to be testing to test it. If this was live beta'ed earlier this year with just a few authors, it still had to, at some point, go through some kind of formal testing procedure and record the results. And there would be a test written specifically to see if X Story Marked Adult would appear if searched from the main page, and one specifically written to check that X Story Marked Adult was showing sales figures, either human-run or automated.
(Crossposted to Livejournal)
{kind=link}
{kind=link}